I was recently forced at gunpoint to estimate the positions of mileposts along the highways in Maricopa County. This was to estimate stops and arrest positions for law enforcement. Like the DPS stop I saw today on I-17 early this morning involving a scooter and a pickup truck. Thanks for making me sit in traffic again. And why are you riding a scooter at 5:30 in the morning when it’s 36 degrees out? You know who you are. And to you in the pickup truck, why do pickup trucks always get right on my butt on the freeway, and expect me to move to the side? Did you see the Marine Corps sticker on my bumper? There will be no moving to the side. Stop driving like a jackass. You are only marginally better than the guy who plays the card fantasy game Dominion and argues about why it pays to buy copper in the game.
Where was I? Oh yeah, calculation of mileposts. By the way, this method is unscientific, inaccurate, and if you use it for important stuff, everyone on the planet Earth will die a horrible death. Consider that a disclaimer. Here is your materials list:
- A copy of RStudio
- A set of incomprehensible law enforcement address data, where the addresses are speckled with milepost stops.
- 32 ounces of coffee
- Two fifths of Islay Scotch, or a cup of Chai tea for those of you that play Dominion
- (Optional, milepost map for Arizona highways, and county and highway shapefiles for plotting)
Here’s a tantalizing glimpse of where we’re going with all this:

This is for highways in Maricopa County, Arizona by the way.
Let’s load the libraries you’ll need:
library("RJSONIO")'
library("ggmap")
library("fossil")
library(rgdal)
library(stringr)
Now I have some functions for gis that I mentioned in previous posts to calculate distances and bearings, and trig identities that I haven’t used since I was an undergrad.
deg2rad <- function(deg) return(deg*pi/180)
rad2deg <- function(rad) return((rad*180)/pi)
#given the distance d that we want our grid to be, and a true course (tc)
#find the lat/longs of the grid centroids
disBearingToPos<-function (lon1,lat1, d, tc) {
#calculates a lat long given an initial lat long
# a distance d in km and a true course tc
#first convert everything into radians
lon1<-deg2rad(lon1)
lat1<-deg2rad(lat1)
#convert true course to radians
tc<-deg2rad(tc)
#radius of the earth in km
R<-3959 #in miles
#convert distance into radial distance
d<-d/R
lat2=asin(sin(lat1)*cos(d)+cos(lat1)*sin(d)*cos(tc))
lon2=lon1+atan2(sin(tc)*sin(d)*cos(lat1), cos(d)-sin(lat1)*sin(lat2))
#convert back
lat2<-rad2deg(lat2)
lon2<-rad2deg((lon2))
return(c(lon2,lat2))
}
#finds the bearing aka true course (tc) between two positions
getBearing<-function(lon1, lat1, lon2, lat2) {
#lon1<-deg2rad(lon1)
lat1<-deg2rad(lat1)
#lon2<-deg2rad(lon2)
lat2<-deg2rad(lat2)
lambda<-deg2rad(lon2-lon1)
Y<-sin(lambda)*cos(lat2)
X<-cos(lat1)*sin(lat2)-sin(lat1)*cos(lat2)*cos(lambda)
tc<-atan2(Y,X)
tc<-rad2deg(tc)
if (tc<0.0) {
tc<-360+tc
}
tc
}
I’m going to use these functions by taking a series of milepost lat-lon positions that I extrapolated with the Arizona milepost map, google map searches, and a lot of swearing. The milepost positions are placed every ten miles or so. I’m going to take these positions and extrapolate mileposts between them at every mile. Kinks in the road are duplicated where possible, but you read the disclaimer. Don’t kill the planet. Here the extrapolation function:
# this function extrapolates mileposts positions between two known positions
make_mms<-function(lon_vector, lat_vector, milepost_vector) {
bear<-getBearing(lon_vector[1],lat_vector[1], lon_vector[2],lat_vector[2])
next_pos<-disBearingToPos(lon_vector[1],lat_vector[1], 1, bear)
k_start<-2
lon_list=list()
lat_list=list()
lon_list[[length(lon_list)+1]]<-lon_vector[1]
lat_list[[length(lat_list)+1]]<-lat_vector[1]
mms<-seq(milepost_vector[1], milepost_vector[2])
mm_list<-as.list(mms)
k_end<-length(mms)-1
if (k_end>1){
for (k in c(k_start:k_end)){
next_pos<-disBearingToPos(lon_list[[k-1]],lat_list[[k-1]], 1, bear)
lon_list[[length(lon_list)+1]]<-next_pos[1]
lat_list[[length(lat_list)+1]]<-next_pos[2]
}
}
lon_list[[length(lon_list)+1]]<-lon_vector[2]
lat_list[[length(lat_list)+1]]<-lat_vector[2]
list(lon_list, lat_list, mm_list)
}
Now we need a function that will take the data we made from the milepost map, and make a dataframe for a highway given that data and using the extrapolation function above:
#this function uses the extrapolation function above, takes a hiway milepost data vector
#and builds a dataframe with highway identification and mileposts along the entire length
#of the data
build_mm_df<-function(lon_vector, lat_vector, milepost_vector, hiway){
road<-rep(hiway, length(lon_vector))
#bear<-getBearing(lon_vector[1],lat_vector[1], lon_vector[2],lat_vector[2])
lon_list<-list()
lat_list<-list()
mm_list<-list()
for (marker in c(1:(length(milepost_vector)-1))) {
temp_lol<-make_mms(lon_vector[marker:(marker+1)], lat_vector[marker:(marker+1)], milepost_vector[marker:(marker+1)])
lon_list<-c(lon_list,temp_lol[[1]])
lat_list<-c(lat_list, temp_lol[[2]])
mm_list<-c(mm_list, temp_lol[[3]])
}
longs<-unlist(lon_list)
lats<-unlist(lat_list)
mms<-unlist(mm_list)
hw_desc<-rep(hiway, length(mms))
mm_df<-data.frame(mms, longs, lats, hw_desc)
#remove duplicated milemarkers from joining
mm_df<-unique(mm_df)
mm_df
}
Since you’ve made it this far, I’m going to give you the milepost data that I extrapolated, using measuring methods that rival those of 14th century alchemist.
#build mile marker to latlon grid
#I-8
mm_ll<-c(32.834,32.842,32.849,32.925,32.940,32.932,32.922,32.911,32.858,32.836)
mm_lo<-c(-112.137,-112.255,-112.319,-112.671,-112.734,-112.803,-112.889,-112.959,-113.213,-113.358)
mm_mo<-c(151,144,140,119,115,111,106,102,87,78)
road<-rep("I8", length(mm_ll))
mm_df<-build_mm_df(mm_lo, mm_ll, mm_mo, "I-8")
#SR-85 from 0 to 33
mm_ll<-c(32.940, 32.819,32.683,32.551,32.509)
mm_lo<-c(-112.734,-112.799,-112.853,-112.880,-112.881)
mm_mo<-c(0,10,20,30,33)
mm_df<-rbind(mm_df, build_mm_df(mm_lo, mm_ll, mm_mo, "SR85"))
#SR-85 from mm 120 to 154
mm_ll<-c(32.94,33.099,33.239,33.389,33.426)
mm_lo<-c(-112.71,-112.647,-112.643,-112.625,-112.626)
mm_mo<-c(120,130,140,150,154)
mm_df<-rbind(mm_df, build_mm_df(mm_lo, mm_ll, mm_mo, "SR85"))
#I-10
mm_ll<-c(33.569,33.538,33.497,33.482,33.428)
mm_lo<-c(-113.352,-113.156,-112.937,-112.868,-112.624)
mm_mo<-c(69,81,94,98,112 )
mm_df<-rbind(mm_df, build_mm_df(mm_lo, mm_ll, mm_mo, "I-10"))
mm_ll<-c(33.428, 33.461, 33.462,33.460, 33.458,33.459)
mm_lo<-c(-112.624,-112.504,-112.462,-112.375,-112.358,-112.306)
mm_mo<-c( 112, 120, 122, 127, 128,131 )
mm_df<-rbind(mm_df, build_mm_df(mm_lo, mm_ll, mm_mo, "I-10"))
mm_ll<-c(33.459, 33.461, 33.462, 33.463, 33.462, 33.461, 33.428)
mm_lo<-c(-112.306, -112.289, -112.238, -112.169, -112.108, -112.038, -112.036)
mm_mo<-c(131, 133, 135, 139, 143, 147, 150)
mm_df<-rbind(mm_df, build_mm_df(mm_lo, mm_ll, mm_mo, "I-10"))
mm_ll<-c(33.428, 33.412, 33.409, 33.378, 33.349, 33.297, 33.118)
mm_lo<-c(-112.036, -112.011, -111.973, -111.968, -111.972, -111.972, -111.842)
mm_mo<-c(150, 151, 153, 154, 157, 161, 175)
mm_df<-rbind(mm_df, build_mm_df(mm_lo, mm_ll, mm_mo, "I-10"))
#US60
mm_ll<-c(33.387, 33.387)
mm_lo<-c(-111.581, -111.969)
mm_mo<-c(194, 172 )
mm_df<-rbind(mm_df, build_mm_df(mm_lo, mm_ll, mm_mo, "US60"))
mm_ll<-c(33.480, 33.594, 33.610, 33.681, 33.864)
mm_lo<-c(-112.114, -112.260, -112.315, -112.404, -112.634)
mm_mo<-c(160, 151, 154, 142, 120 )
mm_df<-rbind(mm_df, build_mm_df(mm_lo, mm_ll, mm_mo, "US60"))
mm_ll<-c(33.864, 33.971, 33.942, 33.943, 33.890)
mm_lo<-c(-112.634, -112.727, -112.904, -113.174, -113.334)
mm_mo<-c(120, 110, 100, 84, 74)
mm_df<-rbind(mm_df, build_mm_df(mm_lo, mm_ll, mm_mo, "US60"))
#SR202
mm_ll<-c(33.297, 33.292, 33.291, 33.287, 33.287, 33.283, 33.283)
mm_lo<-c(-111.972, -111.946, -111.890, -111.876, -111.839, -111.824, -111.768)
mm_mo<-c(55, 53, 50, 49, 47, 46, 41 )
mm_df<-rbind(mm_df, build_mm_df(mm_lo, mm_ll, mm_mo, "SR202"))
mm_ll<-c(33.283, 33.306, 33.326, 33.332, 33.387, 33.430, 33.451, 33.474)
mm_lo<-c(-111.768, -111.739, -111.734, -111.651, -111.648, -111.638, -111.670, -111.686)
mm_mo<-c(41, 40, 39, 34, 30, 27, 24, 23)
mm_df<-rbind(mm_df, build_mm_df(mm_lo, mm_ll, mm_mo, "SR202"))
mm_ll<-c(33.474, 33.475, 33.481, 33.482, 33.466, 33.466, 33.455, 33.434, 33.439, 33.455, 33.462)
mm_lo<-c(-111.686, -111.701, -111.718, -111.753, -111.785, -111.820, -111.840, -111.891, -111.965, -111.972, -112.037)
mm_mo<-c(23, 22, 21, 19, 17, 15, 13, 9, 5, 4, 1)
mm_df<-rbind(mm_df, build_mm_df(mm_lo, mm_ll, mm_mo, "SR202"))
#SR 101
mm_ll<-c(33.292, 33.524, 33.553, 33.564, 33.647, 33.662, 33.673)
mm_lo<-c(-111.894, -111.889, -111.879, -111.889, -111.893, -111.943, -111.977)
mm_mo<-c(61, 45, 43, 42, 36, 33, 31)
mm_df<-rbind(mm_df, build_mm_df(mm_lo, mm_ll, mm_mo, "SR101"))
mm_ll<-c(33.673, 33.672, 33.665, 33.609, 33.594, 33.566, 33.537, 33.508, 33.462)
mm_lo<-c(-111.977, -112.031, -112.229, -112.244,-112.260, -112.257, -112.270, -112.269, -112.268)
mm_mo<-c(31, 28, 17, 12, 11, 9, 7, 5, 1)
mm_df<-rbind(mm_df, build_mm_df(mm_lo, mm_ll, mm_mo, "SR101"))
#SR347
mm_ll<-c(33.205, 33.250, 33.255)
mm_lo<-c(-111.994, -111.979, -111.948)
mm_mo<-c(174, 177, 179 )
mm_df<-rbind(mm_df,build_mm_df(mm_lo, mm_ll, mm_mo, "SR347"))
#SR303
mm_ll<-c(33.456, 33.678, 33.699, 33.775, 33.769)
mm_lo<-c(-112.427, -112.404, -112.317, -112.273, -112.130 )
mm_mo<-c(1, 20, 27, 34, 46 )
mm_df<-rbind(mm_df, build_mm_df(mm_lo, mm_ll, mm_mo, "SR303"))
#I-17
mm_ll<-c(34.054, 33.968, 33.914, 33.833, 33.684, 33.568, 33.553, 33.481, 33.462)
mm_lo<-c(-112.146, -112.128, -112.145, -112.145, -112.112, -112.117, -112.112, -112.113, -112.108)
mm_mo<-c(242, 236, 232, 227, 215, 207, 206, 201, 200)
mm_df<-rbind(mm_df, build_mm_df(mm_lo, mm_ll, mm_mo, "I-17"))
mm_ll<-c(33.462, 33.430, 33.427)
mm_lo<-c(-112.108, -112.106, -112.036)
mm_mo<-c(200, 198, 194)
mm_df<-rbind(mm_df, build_mm_df(mm_lo, mm_ll, mm_mo, "I-17"))
#SR74
mm_ll<-c(33.864, 33.824, 33.835, 33.827, 33.827, 33.798)
mm_lo<-c(-112.633, -112.382, -112.350, -112.261, -112.261, -112.136)
mm_mo<-c(0, 14, 17, 23, 26, 30)
mm_df<-rbind(mm_df, build_mm_df(mm_lo, mm_ll, mm_mo, "SR74"))
#SR87
mm_ll<-c(33.456, 33.479, 33.559, 33.583, 33.584, 33.683, 33.745, 33.924)
mm_lo<-c(-111.841, -111.828, -111.719, -111.658, -111.608, -111.499, -111.504, -111.451)
mm_mo<-c(177, 180, 188, 193, 196, 205, 210, 223 )
mm_df<-rbind(mm_df, build_mm_df(mm_lo, mm_ll, mm_mo, "SR87"))
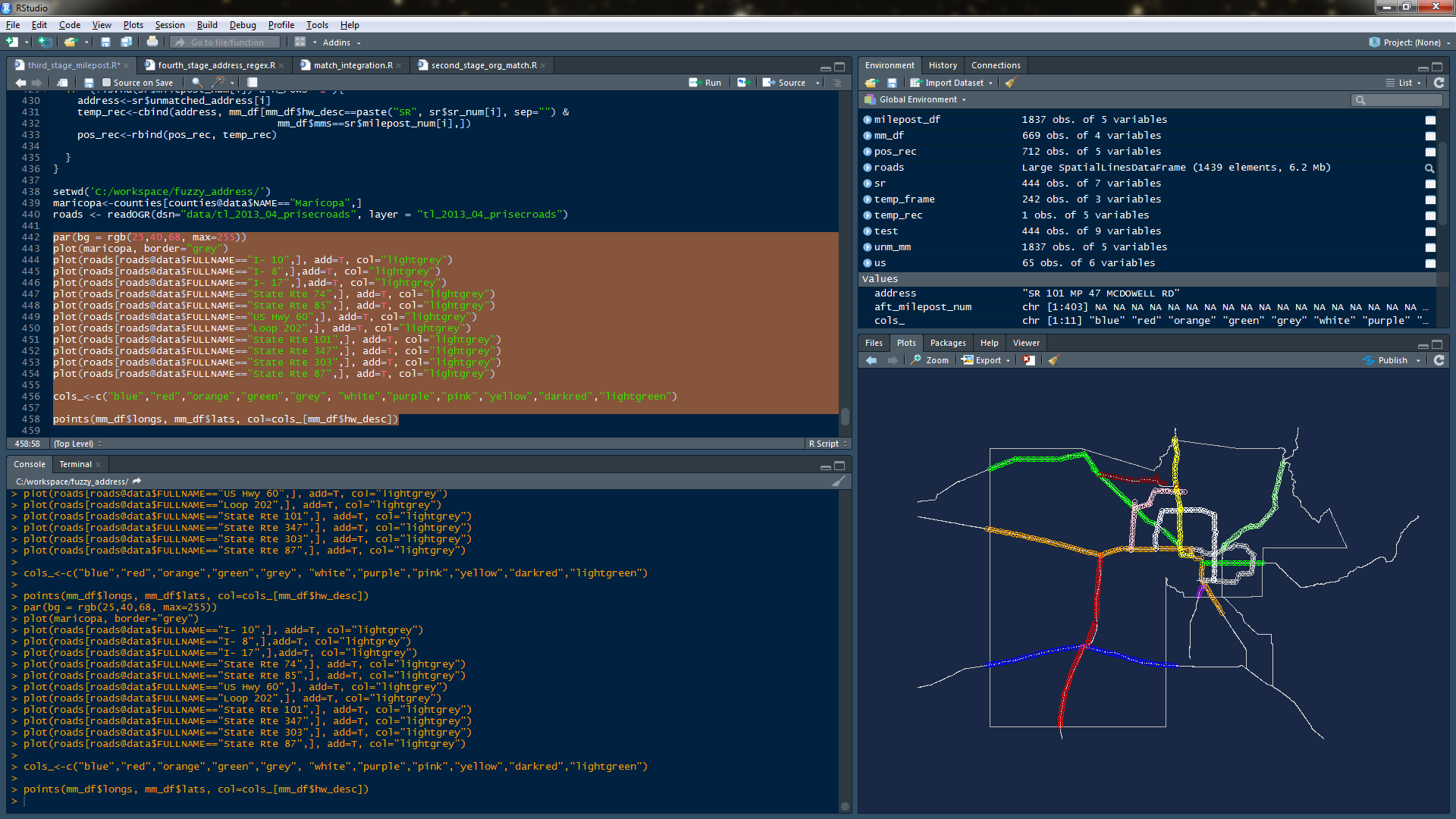
Let’s see what we’ve wrought, by plotting the roads and mileposts on the highways. Our hi-tech analytic approach is this:
Mileposts lined up on the highways = GOOD
Mileposts not on highways = BAD
setwd('C:/workspace/fuzzy_address/')
counties <- readOGR(dsn="data/tl_2016_us_county", layer = "tl_2016_us_county")
maricopa<-counties[counties@data$NAME=="Maricopa",]
roads <- readOGR(dsn="data/tl_2013_04_prisecroads", layer = "tl_2013_04_prisecroads")
par(bg = rgb(25,40,68, max=255))
plot(maricopa, border="grey")
plot_vector<-c("I- 10","I- 8","I- 17","State Rte 74","State Rte 85","US Hwy 60","Loop 202","State Rte 101",
"State Rte 347","State Rte 303","State Rte 87")
plot(roads[roads@data$FULLNAME %in% plot_vector,], add=T, col="lightgrey")
cols_<-c("blue","red","orange","green","grey", "white","purple","pink","yellow","darkred","lightgreen")
points(mm_df$longs, mm_df$lats, col=cols_[mm_df$hw_desc])
If the stars are aligned, your libraries are loaded, then you should see this:
If not, then go back to the ingredients list above. Odds are, you forgot the Scotch. Now we’re coming to the whole point of why we wrote this freakishly long post. If you can remember back that far. If you can, then you forgot the Scotch. We need to take our original law enforcement stop/arrest data and give it latitude and longitude positions. To determine which highways we need to look up the milepost for, we need to use the most painful torture device ever created by the Sith. Yes, I’m talking about
REGEX
Trigger warning. The regular expressions that you’re about to see are horrible. My only excuse, is that using regular expressions for me is like putting my hand on a hot stove, or being burned by acid, or standing on broken glass. In other words, I try to spend as little time there as possible, and get the hell out. Much like a politician in a town meeting right after taxes are raised, or perhaps, a Hollywood celebrity at a substance abuse clinic.
We’re going to sift through are address string data for highway and milepost markers, and get them out.
#route classification I = interstate patt<-"[I|INTERSTATE]\\s?\\-?[8|10|17]" interstate<-milepost_df[grepl(patt,milepost_df$unmatched_address, perl = T),] #SR = state route patt<-"SR" interstate<-interstate[!grepl(patt,interstate$unmatched_address),] patt<-"RAMP" interstate<-interstate[!grepl(patt,interstate$unmatched_address),] #us = US highway #patt<-"US" patt<-"[I|INTERSTATE]\\s?\\-?\\d\\d?\\d?" interstate_num<-interstate$unmatched_address[regexpr(patt,interstate$unmatched_address),] interstate_num<-str_match(interstate$unmatched_address, "(I|INTERSTATE)(\\s?\\-?)(8|10|17)")[,4] interstate<-cbind(interstate,interstate_num) interstate<-interstate[!is.na(interstate$interstate_num),] milepost_num<-str_match(interstate$unmatched_address, "(MM|MP|MILEPOST|MILE POST)(\\.*\\s*\\-*)(\\d\\d*)")[,4] aft_milepost_num<-str_match(interstate$unmatched_address, "(\\d\\d*)(MM|MP|MILEPOST|MILE POST)")[,2] ifelse(!is.na(aft_milepost_num),aft_milepost_num, milepost_num ) interstate<-cbind(interstate,milepost_num) interstate<-interstate[!is.na(interstate$milepost_num),] patt<-"(U\\.*S\\.*)(\\.*\\s*\\-*)60" #us = US highway us<-milepost_df[grepl(patt,milepost_df$unmatched_address, perl = T),] milepost_num<-str_match(us$unmatched_address, "(MM|MP|MILEPOST|MILE POST)(\\.*\\s*\\-*)(\\d\\d*)")[,4] us<-cbind(us,milepost_num) us<-us[!is.na(us$milepost_num),] patt<-"74|85|87|101|202|303|347" sr<-milepost_df[grepl(patt,milepost_df$unmatched_address, perl = T),] sr$sr_num<-str_match(sr$unmatched_address,patt) patt<-"(.*)(MM|MP|MILEPOST|MILE POST)(\\-*)(\\s*)(\\d\\d*)(.*)" sr$milepost_num<-str_match(sr$unmatched_address,patt)[,6] patt<-"(.*)(74|87|85|101|202|303|347)(.*)(MM|MP|MILEPOST|MILE POST)(\\-*)(\\s*)(\\d\\d*)(.*)" temp_frame<-data.frame(str_match(sr$unmatched_address,patt)) temp_frame[!is.na(temp_frame$X1),] temp_frame<-get_sr_matches(sr$unmatched_address, patt, c(3,8))
Thank god that’s over. For the last, we’ll attach these extracted highway-milepost data to our estimated positions for the mileposts. At this point, I’m exhausted and not even going to put these into a function:
pos_rec<-cbind(address,
mm_df[mm_df$hw_desc==paste("I-", interstate$interstate_num[2], sep="") &
mm_df$mms==interstate$milepost_num[2],])
for (i in c(1:nrow(interstate))){
n_rows<-nrow( mm_df[mm_df$hw_desc==paste("I-", interstate$interstate_num[i], sep="") &
mm_df$mms==interstate$milepost_num[i],])
if (!is.na(interstate$milepost_num[i]) & n_rows==1 ){
address<-interstate$unmatched_address[i]
temp_rec<-cbind(address,
mm_df[mm_df$hw_desc==paste("I-", interstate$interstate_num[i], sep="") &
mm_df$mms==interstate$milepost_num[i],])
pos_rec<-rbind(pos_rec, temp_rec)
}
}
for (i in c(1:nrow(us))){
n_rows<-nrow( mm_df[mm_df$hw_desc=="US60" &
mm_df$mms==us$milepost_num[i],])
if (!is.na(us$milepost_num[i]) & n_rows==1 ){
address<-us$unmatched_address[i]
temp_rec<-cbind(address,
mm_df[mm_df$hw_desc=="US60" &
mm_df$mms==us$milepost_num[i],])
pos_rec<-rbind(pos_rec, temp_rec)
}
}
for (i in c(1:nrow(sr))){
n_rows<-nrow( mm_df[mm_df$hw_desc==paste("SR", sr$sr_num[i], sep="") &
mm_df$mms==sr$milepost_num[i],])
if (!is.na(sr$milepost_num[i]) & n_rows==1 ){
address<-sr$unmatched_address[i]
temp_rec<-cbind(address, mm_df[mm_df$hw_desc==paste("SR", sr$sr_num[i], sep="") &
mm_df$mms==sr$milepost_num[i],])
pos_rec<-rbind(pos_rec, temp_rec)
}
}
Let’s plot the positions, and see how we did:
par(bg = rgb(25,40,68, max=255)) plot(maricopa, border="grey") plot(roads[roads@data$FULLNAME %in% plot_vector,], add=T, col="lightgrey") points(pos_rec$longs, pos_rec$lats, col="brown", pch=3)
And you should see:
